

【導讀】本文介紹了一種共享高速存儲器模塊的設計。該高速存儲器能夠實現(xiàn)多核處理器間的數(shù)據(jù)交換,同時占用較小的電路面積。相比傳統(tǒng)的多核處理器數(shù)據(jù)交換方式,本設計可以更好地提升系統(tǒng)性能。是一種有市場競爭力的電路設計結構。
高速緩存作為中央處理器 (CPU) 與主存之間的小規(guī)??焖俅鎯ζ鳎鉀Q了兩者數(shù)據(jù)處理速度的平衡和匹配問題,有助于提高系統(tǒng)整體性能。多處理器 (SMP) 支持共享和私有數(shù)據(jù)的緩存,Cache 一致性協(xié)議用于維護由于多個處理器共享數(shù)據(jù)引發(fā)的多處理器數(shù)據(jù)一致性問題。論述了一個適用于64位多核處理器的共享緩存設計,包括如何實現(xiàn)多處理器緩存一致性及其全定制后端實現(xiàn)。
1.共享緩存結構設計
1.1 總體考慮
在多核 CPU中共享高速緩存主要負責緩存多個處理器核的數(shù)據(jù),處理訪問這些數(shù)據(jù)的缺失請求并向 DRAM 控制器發(fā)送請求以獲得 DRAM 返回的數(shù)據(jù)。共享高速緩存通過交叉開關總線與各個處理器核互連,通過交叉開關總線轉發(fā)通信數(shù)據(jù)包進行數(shù)據(jù)通信。共享高速緩存分為四個緩存組,每個緩存組采用組相聯(lián)地址映射。每個處理核心都可以發(fā)送數(shù)據(jù)包到任意一個緩存組,同數(shù)據(jù)包也可以反方向發(fā)送從任意一個緩存組到任意一個處理核心。
共享緩存采用四路組相聯(lián)映射,將緩存分1024 組。緩存塊的物理地址分為3部分,包括標簽塊、索引塊以及塊內(nèi)偏移。索引部分用于確定緩存塊所在的組。通過比較物理地址的標簽塊和所選中組內(nèi)的四路標簽,可以確定訪問的命中或者缺失。在命中時,比較的結果作為路選擇向量發(fā)往數(shù)據(jù)陣列。緩存通過路選擇向量和組選擇向量確定。
1.2 緩存一致性
對稱式共享存儲器多處理器系統(tǒng)中多處理器2高速緩存子系統(tǒng)共享同一個物理存儲器,通過總線連接,對于所有的處理器訪問存儲器的時間一致,即均勻存儲訪問 (UMA)。對稱式共享存儲器系統(tǒng)支持共享和私有數(shù)據(jù)的緩存。私有數(shù)據(jù)被單個處理器使用,而共享數(shù)據(jù)則被多個處理器使用,通過讀寫共享數(shù)據(jù)完成處理器之間的通信。共享數(shù)據(jù)在多個緩存中形成副本,減少了訪問時延、降低了對存儲器帶寬的要求并減少多個處理器讀取共享數(shù)據(jù)時的競爭現(xiàn)象。然而,共享數(shù)據(jù)帶來了緩存一致性問題,實現(xiàn)緩存一致性關鍵在于跟蹤所有共享數(shù)據(jù)塊的狀態(tài)。目前為了實現(xiàn)緩存一致性而廣泛采用的有目錄式以及監(jiān)聽式這兩種協(xié)議。該設計采用目錄式緩存一致性協(xié)議 ,把物理存儲器的共享狀態(tài)放在目錄表中,根據(jù)目錄跟蹤哪一個以及緩存擁有二級緩存塊的副本。一級緩存是寫直達的,只有無效信息被要求,共享緩存是寫回的,數(shù)據(jù)總可以從共享緩存中重新得到。為減少目錄的開銷,將目錄放在緩存中而不是存儲器中。
當一個塊還未被緩存有 2 種可能的目錄請求:
1) 讀缺失:共享緩存向發(fā)出請求的處理器送回所要求的數(shù)據(jù),發(fā)送請求的節(jié)點成為唯一的共享節(jié)點。塊的狀態(tài)設為共享。
2) 寫缺失:向發(fā)出請求的處理器送回數(shù)據(jù)并使它成為共享節(jié)點。數(shù)據(jù)塊設為獨占狀態(tài),指明這是唯一有效的緩存副本。共享者集合中指明所有者。當數(shù)據(jù)塊處于共享狀態(tài)時,共享緩存中的值是最新的,有 2 種可能的目錄請求:
1) 讀缺失:共享緩存向發(fā)送請求的處理器送回所要求的數(shù)據(jù),并將發(fā)送請求的處理器放到共享集中。
2) 寫缺失:向發(fā)送請求的處理器送回數(shù)據(jù),無效共享集合中的處理器緩存塊,保存發(fā)送請求的處理器標識,將數(shù)據(jù)塊設置成獨占狀態(tài)。
當數(shù)據(jù)塊處于獨占狀態(tài)時,塊的當前值保存在共享者集所指明的處理器的緩存中,有 3 種可能的目錄請求:
1) 讀缺失:向所有者處理器發(fā)送數(shù)據(jù)消息,將緩存塊狀態(tài)設為共享。由所有者向目錄發(fā)送數(shù)據(jù),將數(shù)據(jù)寫入共享緩存并發(fā)送回發(fā)出請求的處理器。再將發(fā)出請求的處理器添加到共享者集合中,這時集合中仍然會有其他所有者處理器。
2) 數(shù)據(jù)寫回:執(zhí)行寫回操作,更新存儲器副本 ,共享者集合為空。
3) 寫缺失:數(shù)據(jù)塊有了新的所有者。向舊的所有者發(fā)送消息,使緩存將該數(shù)據(jù)塊設置為無效,并把值發(fā)送到目錄中,再通過目錄把數(shù)值發(fā)送到發(fā)出請求的處理器上。發(fā)出請求的處理器成為新的所有者。共享者集合只保留新所有者的標識,而塊仍然處于獨占狀態(tài)。
2.高速共享緩存模塊
用戶RAM大小為2MB,掛接在雙核之間的AHB總線上,兩個內(nèi)核訪問區(qū)域可以任意配置。其內(nèi)部是一塊 SRAM 和AHB總線從接口電路,如圖2-1所示。讀訪問有一個周期的延遲,寫訪問無延遲。讀寫訪問時序見圖2-2、圖2-3。讀寫都支持字節(jié)(byte)訪問、半字(half-word)訪問或字(word)訪問。
用戶RAM所在的地址空間范圍為0xA0000000 ~ 0xA01FFFFF。
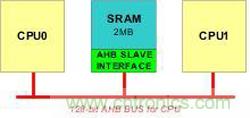
圖 2?1 用戶RAM結構示意圖
假設CPU0寫數(shù)據(jù)到用戶RAM,接著CPU1從用戶RAM讀數(shù)據(jù)。這種情況下,CPU0首先寫數(shù)據(jù),然后將標志變量置1,表示用戶RAM內(nèi)的數(shù)據(jù)已更新。標志變量地址位于用戶RAM地址范圍內(nèi)。接著CPU1讀標志變量,若變量為1,則從用戶RAM內(nèi)對應地址讀取CPU0寫入的數(shù)據(jù),并將標志變量置0;若標志變量為0,則表示用戶RAM內(nèi)數(shù)據(jù)已被CPU1讀取過。
使用以上方法可實現(xiàn)核間數(shù)據(jù)交互。由于同一時刻AHB總線上只能有一個設備利用總線進行讀寫,所以可以保證讀寫操作的原子性,即標志變量不可能被CPU0和CPU1同時訪問。從而保證了標志變量的有效性。
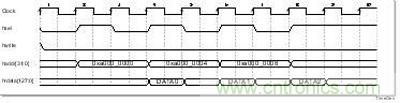
圖 2?2 用戶RAM讀時序
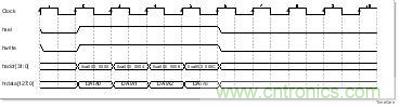
圖 2?3 用戶RAM寫時序




